A Timeline for Artificial Intelligence
The following essay covers machine learning from its infant days to full self-driving. I intend to crystallise how and why computers have developed in the way they have, and why future machines will be far more advanced.
Contents:
-
The Architecture of Intelligence
-
Progression by Decade (1940s-2020s)
-
The AI Pantheon
"A.I. began with an ancient wish to forge the Gods" - Pamela McCordick
The First Step was going from inanimate matter to matter that could solve simple problems by computation.
The Second Step was going from matter that could compute, to matter that could solve broad problems autonomously.
The Third Step will take matter that exhibits intelligence and give it the power to rewire itself for learning better without bounds. This third step is known as the singularity.
In 2022, the first step is well understood. The second stage is well underway. The third will very likely occur within our lifetime.
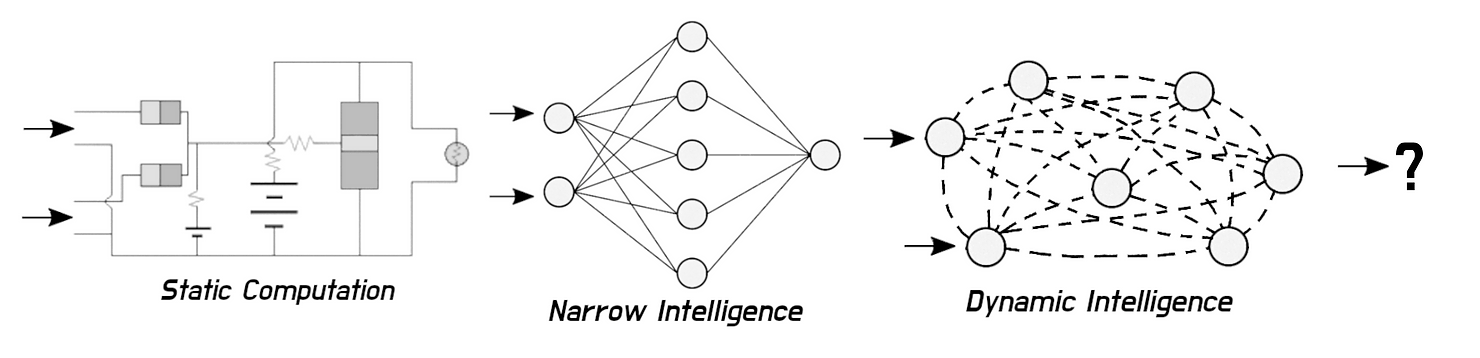
Figure 1. The three paradigm shifts in computation.
Part I. The Architecture of Intelligence
Of all the changes we will see in our lifetime, none will compare to the force of artificial intelligence. Reasoning machines will create a significant amount of disruption in every industry and generate billions of economic value in the process. Understanding how will enable us to act with more precision.
Until the 21st century, AI was in its infancy and suffered from incessant springs and winters. Funding would explode and then dry up based on media hype. While progress has not been as consistent as trends in computational power over the same period, it has progressed from nothing at its inception around sixty years ago, to ‘narrowly superhuman’ in 2021.
The founders of artificial intelligence are generally seen as John McCarthy, Alan Turing, Marvin Minsky, Allen Newell, and Herbert Simon in the 1950s and 1960s. The founding motivation was that computers excel at executing precise instructions in consistent fashion, and by describing a problem in natural language to a computer, we can use algorithms to come up with the perfect solution every time. If an algorithm is advanced enough, it would be able to solve large problems, such as driving, policy making, science, and everything in between.
Progression by Decade
1940s
Alan Turing develops the Bombe machine at Bletchley Park with codebreaker Gordon Welchman by cracking the enigma code with brute-force computation. This effort is believed to have shortened the second World War. Turing would become a founding father of computer science and artificial intelligence over the next 13 years before his untimely death.
Claude Shannon founded information theory in the early 1940s by inventing the bit, and describing the digital codes that would make it possible for engineers to compress and accurately transmit information. Shannon would write extensively on chess algorithms and would live to 2001.
Shannon met Alan Turing, the father of computer science, in 1943 at Bell Labs. They reportedly wrote programs to play chess before computers existed that could even run their code.

Figure 2. Neuroscientist Warren McCulloch (Left) and Logician Walter Pitts (Right).
The first mathematical model for artificial intelligence was based off the neuron, called the “Threshold Logic Unit” by Warren McCulloch and Walter Pitts Jr in 1943. Although very simple, their model was proven extremely versatile and easy to modify, with the artificial neuron being the building block for machine intelligence in the generations to come.
The McCulloch & Pitts neuron model has been unchanged in the 90 years since its conception. On a basic level, it can be defined as having:
-
A binary output y ∈ {0, 1}, where y = 1 indicating that the neuron fires and y = 0 indicating it is at rest.
-
N number of binary inputs xₖ ∈ {0, 1}.
-
A single inhibitory input i; if it is on, the neuron cannot fire.
-
A threshold value Θ. If the sum of its inputs is larger than this critical value, the neuron fires. Otherwise, it stays at rest. [1]
Given the input x = [ x₁, x₂, x₃, …, xₙ ]ᵀ, the inhibitory input i and the threshold Θ, the output y is computed as follows:
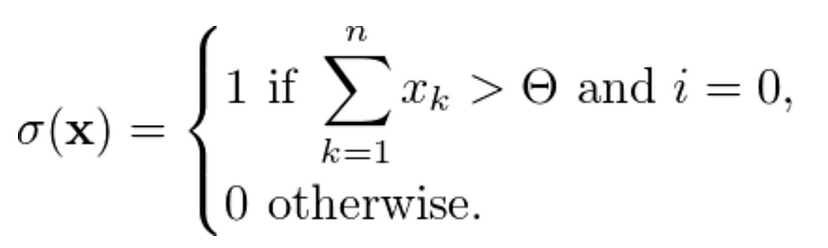
In 1949, Donald Hebb published ideas about unsupervised learning in ‘The Organisation of Behaviour’. Hebbian theory attempts to explain synaptic plasticity, or how neurons adapt during the learning process, and Hebbian learning functions are still used in some stochastic update algorithms for neural networks.
1950s
In 1950, Alan Turing devised the “Turing Test” for future generations to determine whether a computer has human level intelligence. To pass the test, a computer must convince a human that it is also human.
Arthur Samuel wrote the first computer learning program in 1952 in the form of a game of checkers. He developed at IBM a program that improved its gameplay with new iterations, incorporating winning strategies into its game tree program. With this code, Samuel coined the term ‘machine learning’.
In 1956, automata theory was as close a field as you could get to computer science. John McCarthy and Marvin Minsky distinguished these fields on a panel with Claude Shannon and Nathaniel Rochester at Dartmouth college. They created the term ‘Artificial Intelligence’, a contrary field to cybernetics, though had reservations about the term ‘artificial’. Objections were over the fact that ‘artificial’ implies insincerity and falseness, when all it is intended to mean is inorganic.
In reality, human-like, “real-world” intelligence and its many features are all conceptually achievable by machines. Oxford define intelligence as ‘the ability to acquire and apply knowledge and skills;’ no part of this definition that is limited to the biological mind.
At this point in time, there was significant discussion about the underlying nature of intelligence. Two main pillars of thought emerged: ‘symbolic’ and ‘sub-symbolic’ AI. Advocates for symbolic AI included Allen Newell and Herbert Simon, who cited that intelligence is logical, and that by us defining rules as logic puzzles, algorithms can solve real-world problems.
During the 1960s, symbolic approaches achieved great success at simulating intelligent behaviour in small demonstration programs, becoming the dominant approach over other approaches based off cybernetics or artificial neural networks. But this would not last.
It became evident that symbolic systems needed huge amounts of supervision, and for broader problems that cannot be programmed in simply with rules, such as walking or recognising written and spoken language, this approach would be unfeasible. This is known as combinatorial explosion; as problems become exponentially more complex with wider inputs, constraints, and bounds, a problem’s complexity rapidly increases (requiring more labour setup, training, and debugging).
Symbolic intelligence was first referred to as ‘Good Old-Fashioned Artificial Intelligence’, or GOFAI, in 1985 by John Haugeland. While ‘old-fashioned’ is used partly in jest in this sense, symbolic systems are essentially variants of linear regressors dating back two centuries (to Gauss and Legendre). On the other hand, sub-symbolic intelligence is a model based off the human mind, or, in the words of philosopher Andy Clark, “bad at logic, good at frisbee”. They are constructed from a broader architecture known fittingly as a ‘neural network’, where connections, similar to synaptic pathways, strengthen the more they are used.
In the field of sub-symbolic intelligence, notable work was achieved by Frank Rosenblatt, who in 1957 developed the ‘Perceptron’, inspired by the role of the neuron as the building block of the brain. It works by taking multiple inputs and having one output. The perceptron sums inputs, and outputs 1 or 0 depending on if the sum is greater than or equal to the threshold level. This is very much like the firing of neurons; it is a physical model of McCulloch and Pitts’ artificial neuron that decides ‘yes’ or ‘no’ based on simple bit inputs.
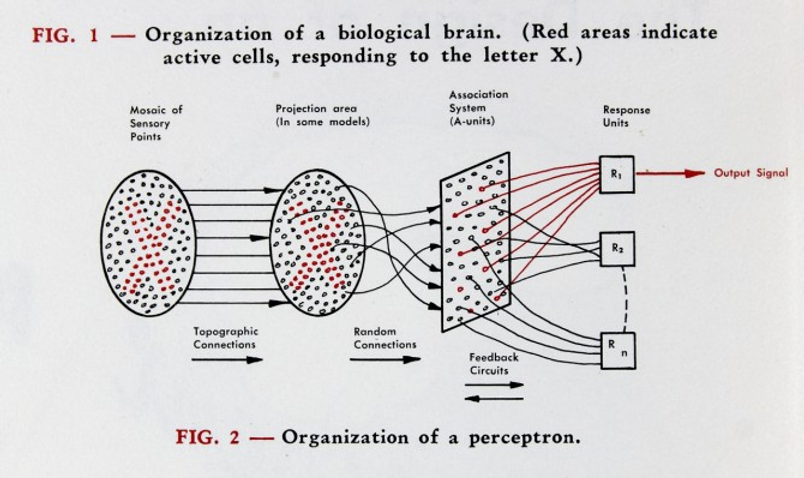
Figure 3. The perceptron from Rosenblatt’s “The Design of an Intelligent Automaton,” 1958.

Figure 4. Frank Rosenblatt and the Mark 1 Perceptron machine, the first implementation of the perceptron algorithm. [2]
Rosenblatt believed an array of perceptrons could tell apart cats from dogs, but this was an overestimation. Perceptrons are only capable of telling apart cats from dogs in far more sophisticated networks than what he suggested. “Training sets” are datasets that can enable a neural network’s parameters to interpret new inputs usefully. Labelling data enables positive and negative examples to be enlisted, teaching a network what is right and what is wrong. No scalable method for training a network was developed for another three decades.
1960s
In 1967, the ‘nearest neighbour’ algorithm was written, allowing computers to use very basic pattern recognition. The networking algorithm was similar to Dijkstra’s 1956 algorithm and could be used by travelling salesmen to map a route most efficiently from input cities, for example.
The origin of deep learning networks began with Ivakhenko and Lapa (1965) publishing the first general, working training algorithm for supervised feed-forward neural networks. Ivakhenko went on to theorise a deep network with 8 layers trained by ‘Group Method of Data Handling’ in 1971, a practice which would become popular in the new millennium. [3]
Minsky and Papert’s 1969 book ‘Perceptrons’ ruthlessly questioned the capabilities of a single perceptron layer and paved the way for Multilayer Perceptron neural networks (or MLPs). The issue was, however, that training MLPs was extremely difficult. Back-propagation was not scalably-functional yet and essentially did not exist in hardware, only as mathematical theory.
The rivalry between Rosenblatt and Minsky was born from their school years when they were just one year apart. A New Scientist article from the time wrote “During the late 1950s and early 1960s, much to the enjoyment of those in the audience, Rosenblatt and Minsky debated on the floors of scientific conferences the value of biologically inspired computation, Rosenblatt arguing that his neural networks could do almost anything and Minsky countering that they could do little.” [4]
The ‘first AI winter’ followed 1969.
1970s
In 1972, The James Lighthill Report submitted to the British Scientific Research Council on the state of artificial intelligence discredited the techniques being used at the time as ‘unscalable’ to solve real-world problems which would require many, many more parameters than could be accounted for (again citing combinatorial explosion).
Combinatoric explosion explains the rapid heating-and-cooling of AI hype, for when journalists and policy makers grasp the scale of the problems, they have shown to easily lose faith in the technology of these systems. Fortunately, as technology progresses, it seems to follow stepwise exponential growth in capability, making hard problems more manageable over time.
1974 saw a possible end of winter in the artificial intelligence world. Paul Werbos proposed that backpropagation, derived by multiple researchers in the 1960s, could be used for neural nets, inspired by Sigmund Freud’s psychodynamic model of the brain.
Backpropagation, theoretically, would enable nodes to adjust their weights to train a network by using of a ‘loss function’ that tells a computer how well it is performing. More specifically, it is a way of taking on an error and propagating the blame for that error backwards so that all weights can better reflect results. Learning systems are all variations on this foundation. Learning for neural networks means to gradually reduce each output error until it tends to zero for all training examples. This is why the availability of high-quality data is so crucial.

Figure 5. This process can be visualised as a landscape of peaks and valleys, where valleys are performing well and peaks are underperforming. By training on more and more data, the peaks can be ironed out and the overall machine performance can surpass a given ‘usefulness’ threshold (burgundy).
A multi-layer perceptron neural network was proposed by Kunihiko Fukushima in 1975, and called the ‘cognitron’. This neural network was to be compiled of perceptron layers, where each perceptron outputs to every perceptron in the next layer, vastly increasing the potential of a system versus what came before. The depth of perceptron layers in a system determines its ability to compute complexity. Nuances in Fukushima’s 1975 system, however, meant that its ability for pattern recognition was not so high; he recognised that the system was dependent upon the position of the incident stimulus patterns in such a way that it could not learn or be trained reliably.
Fukushima continued his work on this and in 1980 published a paper on the ‘neocognitron’, which was a more sophisticated system now considered to be the original deep convolutional neural network. Several supervised and unsupervised learning algorithms were proposed by Fukushima to train the parameters of a deep neocognitron in a useful way, but no suggestion stood the test of time. It was Werbos’ backpropagation that ostensibly ‘held the torch’ for the supervised training of neural networks. [5]
1980s
Gerald Dejong introduces the Explanation Based Learning system (EBL), where a computer analyses training data and creates a general rule it can follow by discarding unimportant data. This method was effective, but only in limited cases. Combinatoric explosion again makes this symbolic system ineffective at more general tasks. Without a strong case for training neural networks, the next ‘AI winter’ set in around 1983, though work continued, particularly in Europe. Some argue that this second AI winter lasted well into the 2000s. [6]
In 1986, Geoffrey Hinton and colleagues showed that backpropagation could usefully train neural networks. Following this, French scientist Yann LeCun proposed what has become the modern form of the backpropagation learning algorithm for his 1987 thesis. Yann LeCun proposed that convolutional neural networks (ConvNets or CNNs) paired with back propagation held the solution to many of the problems that fell victim to combinatoric explosion previously.
The architecture of CNNs use ‘activation maps’ similar to those discovered by Hubel and Wiesel in the brain in 1964. Yann LeCun’s ‘LeNet’ was an early ConvNet used to recognise handwritten digits. It was used by US postal and banking services, reading over 10% of all the cheques in the US in the late 1990s and early 2000s. ConvNets lost mainstream attention when researchers underestimated the growth in access to data, which would soon occur with the internet’s presence.
Hubel and Wiesel’s 1960s discovery was that when human eyes focus on a scene, they receive light of different wavelengths that have been reflected by the objects and surfaces in the scene. Light waves incident on the eye activate cells in each retina, which operate like neurons. These neurons activate, communicating their activation through the optic nerves and into the visual cortex, which is organised as a hierarchical series of neurons, meaning each layer communicates their activation to neurons in the succeeding layer.
Hubel and Wiesel further found evidence that neurons in different layers of this hierarchy act as ‘detectors’ that respond to increasing resolutions of the visual scene. Neurons initially activate in response to the intensity of light incident on edges and surfaces, then they process information about simple shapes made of these edges. From these, they process more complex shapes, and then from these complex objects, the brain can recognise specific faces that may be familiar or new, for example. This is known as a ‘bottom-up’ or ‘feed-forward’ flow of information, representing connections from lower to higher layers, and is contrary to a ‘top-down’ or ‘feed-backward’ flow of information from higher to lower layers.
The top-down visual system is not as well understood by neuroscience (though fascinatingly there are about 10x as many top-down connections as bottom-up, suggesting it is paramount to our level of perception). Convolutional neural nets are ultimately layers of simulated neurons (or units) with a ‘classification module’ trained to recognise inputs as x, y, or z with a percentage degree of certainty. This was the necessary step for recognising cats from dogs that was missing back when Rosenblatt developed the perceptron.
Between 1979 and 1998, a large number of intelligence architectures were proposed and developed. Recurring Neural Networks (RNNs) can use their internal state (memory) to process variable length input sequences, making for more ‘general’ or ‘broad’ problem solving. Furthermore, RNNs can either be unidirectional or bi-directional, and each system is useful for different functions with varying levels of complexity. Traditional MLPs and Time Delay Neural Networks have limitations on the input data flexibility, as they require input data to be fixed, whereas Bi-directional Recursive Neural Networks do not require their input data to be fixed. These are just some examples of the expansion in the field of neural networks. Networks are said to be ‘Turing complete’ or ‘computationally universal’ when they can simulate any Turing machine, meaning they can implement any computer algorithm.
An ‘AI spring’ is said to have started after 1988 when a top official at DARPA had a statement published: ‘AI will be more important than the atomic bomb’.
1990s
The approach to machine learning shifted over the 1990s from a knowledge-driven approach to a data-driven approach. Big datasets become more important for training programs built on backpropagation. Most notably, the ’90s was a decade where the first ‘holy shit moments’ shook the general public. In the research world, American inventor and futurist Ray Kurzweil predicted in 1990 that a computer would defeat a world chess champion by 1998.
The first defeat of an intellectual world champion was in 1994, when Marion Tinsley, American mathematician and 9-time world champion checkers player, lost to the Chinook computer program 4-2 (with 33 draws). Interestingly, in 1990, Chinook had placed second at the U.S. nationals after Tinsley, who resigned his title in order to play the computer after both the American and English associations refused to allow a computer to play for the title. Tinsley won their first encounter with a stroke of genius, remarking after move ten “You’re going to regret that,” and winning with the only strategy that could have defeated Chinook 64 moves later. He ultimately would lose four years later.
Checkers requires calculating the best of 7 possible moves ahead on average. Chess is considered far more cognitively trying as it requires choosing the best of 35 possible moves ahead, on average. In 1958, Allen Newell and Herbert Simon had remarked that “chess demonstrates the core of the human intellectual endeavour.”
In 1996, IBM’s Deep Blue algorithm plays Garry Kasparov, the world champion, at chess. Kasparov won 4-2. One year later, Deep Blue would win the rematch (3 1/2) - (2 1/2); a year before Kurzweil’s upper-bound prediction. The match has been seen as symbolically significant: humanity’s widely-known intellectual champions could be beaten by a machine.
The win lead to a large amount of controversy over one move where Deep Blue made a sacrifice that seemed to hint at a long-term strategy. The move stunned Kasparov, who had bragged that he would never lose to a machine. Kasparov blamed his defeat on this move, which, fifteen years later, was admitted to be the result of a bug in Deep Blue’s software. Fascinatingly, the symmetry of this match would return two decades later. [7]

Figure 6. Kasparov vs. Deep Blue, 1997.
The meter stick for artificial intelligence thereafter grew longer, with the media and scientists alike pointing to ‘Go’ as the next challenge, and real measure of general intelligence. This moving of goalposts was noted by researchers; John McCarthy had historically observed that “As soon as it works, no one calls it AI anymore,” and in the words of by Claude Shannon, “A machine defeating a human at chess may further restrict our concept of thinking; we’d dismiss the accomplishment over time.” [8]
The New York Times predicted in 1997 that Go was over 100 years away from being won by a machine. Go was not only more vast (250 average possible moves, or 7x more computationally advanced than chess), but also far more strategically complex. Hardware improvements would be needed for the improved computational power, and software improvements would be needed for the increased mathematical complexity. These stages of hype and discrediting can again be attributed to combinatorial explosion; the changing of a few parameters make magnitudes more complexity.
2000s
In the early 2000s the largest use case for AI was still LeCun’s LeNet, built from the MNIST database in 1998. Torch, a software library for machine learning was released in 2002, and the Netflix Prize competition was launched a few years later, challenging teams to beat Netflix’s own recommendation software in predicting a user’s rating for a film given their rating for previous films. This prize was eventually won in 2004.
The Pascal Visual Object Classes (VOC) competition made a dataset of images with labels publicly available for competition between teams in 2005. The number of image categories was later capped at 20, as neural nets would need to train in short periods to recognise input images’ content.
The following year, Geoffrey Hinton, notable for his work in popularising backpropagation for neural networks, coins “Deep Learning” to refer to new algorithms that let computers ‘see’ and distinguish objects and text in images and videos. In the modern day, Hinton, along with his students Yann LeCun and Yoshua Benjio, have become known as the ‘Godfathers of Deep Learning,’ giving many public talks together and sharing the 2018 Turing Award (though many agree the awards left out Jurgen Schmidhuber, a worthy colleague of the field and diligent record-keeper of progress).
In 2006, researcher Fei Fei Li, who believed that the advent of superhuman visual recognition systems could be brought forward with a library of high quality training data, began developing ImageNet. ImageNet is a dataset of hand-tagged images with 1000 categories, 50x broader than the Pascal dataset. To label the significant body of data needed for training, she and fellow researchers used freelancers on the Amazon Mechanical Turk platform (“MTurk”), to tag 3 million images to WordNet nouns over two years.
ImageNet was the first breakthrough in quality data availability that backpropagation and CNNs needed to dominate visual recognition systems in years to come (though its development wasn’t truly ground-breaking until 2012). The second breakthrough was the availability of Graphics Processing Units (GPUs). Growth in processing power and availability was crucial for advancements in neural networks. Andrew Ng, Rajat Raina and Anand Madhavan’s 2009 paper touted a speed increase in large-scale deep unsupervised learning of 70x, due to developments in graphics processors. This is known as the ‘tipping point’ for GPUs, and would contribute to AI by developing in-parallel throughout the 2010s.
2010s
In 2010, the first ImageNet Large Scale Visual Recognition Challenge (ILSVRC) took place, with the winning machine (of 35 competitors) having a top-five accuracy of 71.8% (top-five accuracy refers to the odds of any of five guesses per image being accurate). Human level, for reference, is between 94.9 and 98% accuracy in image recognition for the same giant database.
It should be noted that both top-five accuracy and the human level reference are highly contentious statistics; top-five accuracy is considered a significant dumbing down of intelligence; a machine shown a simple image of a bus might guess “duck, balloon, bike, human, bus” and get a tick, despite its apparent blindness. The human level accuracy of 94.9% was by a Google researcher who did not write down five answers for each image, was mostly comparing dog-breeds, and who reportedly suffered from boredom and tiredness while tagging 1500 different images in a short period of days. 98% accuracy is the level proposed by Melanie Mitchell, in response to the issues of Google’s widely-cited reference level. [9]
In 2011, the winning machine had 25.8% top-five error. Competing machines were not convolutional neural nets, but various methods, including support vector algorithms. Then in 2012, AlexNet (a CNN) stunned the world with just 16.4% top-five error. This jump was done in part by scaling the hidden layers on the neural net (and subsequently scaling up energy requirements and complexity). AlexNet had 8 layers and 60 million weights.
2012 saw plenty of acqui-hiring as big tech realised the potential of ConvNets. LeCun, the ConvNet’s prophetic torchbearer, was poached by Facebook. ConvNets are believed to work so well because:
-
fast training (over 100 layers can be trained in just a few days), and,
-
data availability (CNNs require massive amounts) is high in the modern age.
Subsequently, machine vision improved each year as big tech piled in like an arms race. In 2015 the winner overtook the broad human level estimate, boasting a ‘superhuman’ 3.6% top-five error rate.
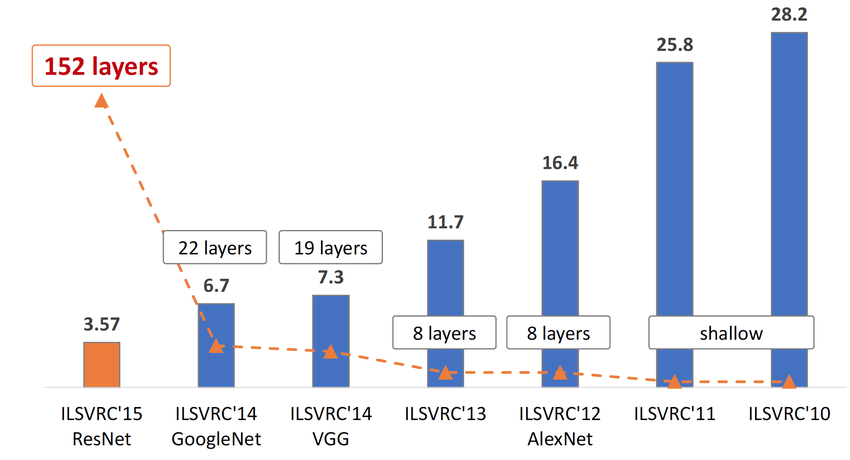
Figure 7. The correlation between top-five accuracy and the number of hidden layers in a convolutional neural network for image recognition.
Arguably the more relevant view of machine performance is top-one accuracy; the more direct, side-by-side comparison to humans. In 2015, the top-one accuracy level for the best algorithm was 82% while human level is around 95%. This level of performance versus what was published by media at the time highlights how hype, again, extends expectations when it comes to AI performance, rarely getting it right.
The AlexNet discovery led to a commercial ‘gold rush’ and first real consumer application of AI. Google Photos rolled out a tagging feature where you could find memories by objects and faces. Google Street View could now blur street addresses and license plates. Facebook filed a patent on facial emotion recognition, while twitter could screen inappropriate links more effectively. Both Google and Microsoft rolled out a ‘find similar images’ feature on their search engines, and Siri and Alexa both leveraged deep network training.
Ultimately, this gold rush is continuing to drive vast amounts of value creation ten years later, with self-driving cars, medical applications and surveillance software using deep convolutional neural networks training on the ImageNet database. GPU manufacturers saw magnitudes more investor interest. In the five years between 2012 and 2017, Nvidia stock rose by 1000%.
Returning to 2011, IBM’s Watson supercomputer took on Jeopardy! by answering riddles and complex questions. Watson trounced its opposition, the two best performers of all time on the show (Ken Jennings and Brad Rutter).
Google Brain is formed that year by Andrew Ng and others with the objective of building a large-scale deep learning software system, DistBelief, in the Google Cloud. DistBelief became TensorFlow in 2017 and was so lucrative that Astro Teller has said that project alone paid for the entire cost of Google X.

Figure 8. The Arcade Learning Environment, released in 2013.
Canadian researchers released the Arcade Learning Environment in 2013, making it easier for testing machine learning systems on 57 Atari 2600 games. This platform became the focus of DeepMind, a company founded in 2010 under the slogan: ‘Solve intelligence, and use it to solve everything else.’ Dennis Hassibis, their colourful and storied founder, viewed video games ‘like microcosms of the real world, but cleaner and more constrained.’
DeepMind, purchased by GoogleAI in 2014, used Deep Q-Learning, temporal difference learning and deep reinforcement learning to train a machine to master the platform without supervision. They initially taught a program to play Breakout, the same game that Steve Jobs coded for Atari. Later, their DQN algorithm (2015) obtained better than 2x human capability in 12% of the games and better than 5x human capability in 6.25% of the games. In 2020, their algorithm ‘Agent57’ obtained a score above the human baseline on all 57 games.
On the Turing Test’s 65th anniversary, an event was held that had 33% of judges convinced that an algorithm was human in a five-minute conversation. This proved much progress was yet to be made.
In 2014, Facebook develops DeepFace, a software to recognise or verify individuals on photos to above the level of human recognition trained with over 1 billion Instagram images. That year, Ian Goodfellow and colleagues created Generative Adversarial Networks (or GANs), which is at its core a system where two neural networks can partially supervise each other. This was paramount in the development over the next few years.
In 2015, Amazon launches its own machine learning platform, and Microsoft creates the Distributed Machine Learning Toolkit, which enables the efficient distribution of machine learning problems across multiple computers.
Over 3,000 AI and Robotics researchers, endorsed by Stephen Hawking, Elon Musk, and Steve Wozniak, signed an open letter warning of the danger of autonomous weapons which select and engage targets without human intervention.
The Winograd Schema Challenge (WSC) was held in 2016 to test computer intelligence ‘more thoroughly’ than the Turing Test, by targeting a machine’s contextual understanding (anaphora). This makes it a task for natural-language-processing intelligence, and requires the application of knowledge and commonsense reasoning.
2016 was ultimately a year that ‘dramatized the progress that [[had]] been made in machine learning over the few years prior,’ according to Nick Bostrom. DeepMind developed AlphaGo, which used deep reinforcement learning (see Superintelligence: Incoming!) to play the ancient game of Go. AlphaGo beat Lee Sedol, the world champion, 4-1, then played the top 20 champions without losing a game. As one of the 4 arts in Chinese culture (along with painting, calligraphy, and qin music), the Go match garnered a vast audience of over 300 million watchers. They were not disappointed.
During the early period of one game, AlphaGo played a highly unexpected move, placing a white stone five spaces from the side and into a juxtaposing position. Chinese commentators said they found it unbelievable, “This is the first time I am seeing AlphaGo making a move like this. It feels like AlphaGo is playing like a human.” Lee Sedol countered, and moments later, AlphaGo blocked him in an astonishing move. The same commentators were dumbfounded, “This can’t be right” one said. Distinctly unlike the previous action, he said “This action is not like a human at all.” The human reaction was a mixture of fear and astonishment, and rightly so; AlphaGo was looking between fifty and seventy moves ahead. This was a very apparent ‘holy shit moment’ for viewers.

Figure 9. Lee Sedol vs AlphaGo, 2016.
Ke Jie, veteran Go champion said following the match, “AI shows us we have not scratched the surface [of Go]… a union of human and computer players will usher in a new era… man and AI can find the truth of Go.”
It has become apparent that what Ke Jie says here applies not just to Go, but to everything. Technology combined with sports help us understand ‘the truth’ of performance. In the 100m swim freestyle, for example, female champions are swimming by the late 2000s as fast as men in the 1970s. Women have not evolved to swim faster in that time, and biological anomaly cannot be attributed to these gains in performance. It is the product of an improved understanding about technique, training, and nutrition that drove this frontier.
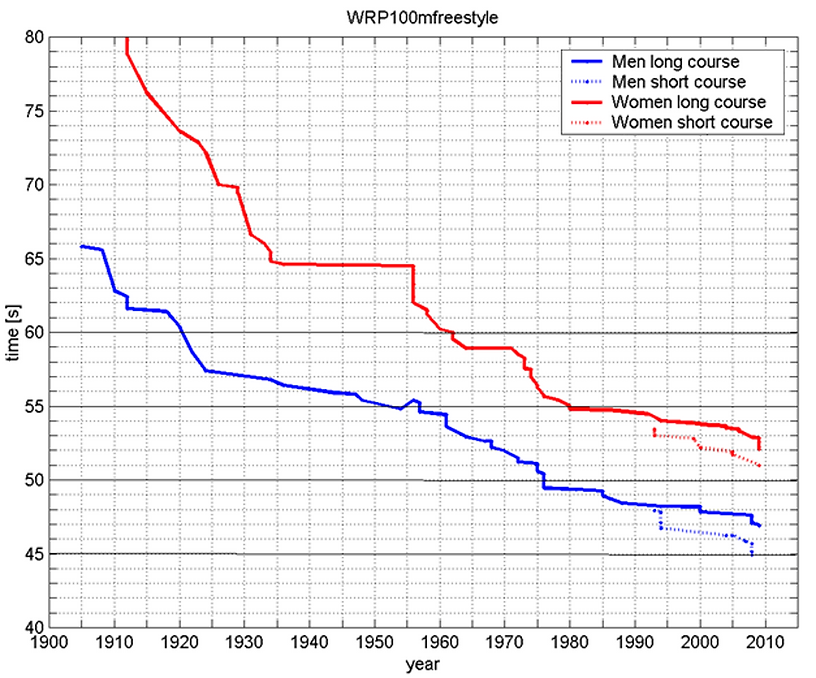
Figure 10. Understanding dictates performance, here shown with the 100m freestyle.
With accurate simulations and the application of neural networks, AI can help us find both conventional and unconventional solutions. This is nowhere more apparent than in the game of AlphaGo and Lee Sedol.
Two years later, AlphaGo Zero, the successor to AlphaGo, started only with knowledge of the rules; no opponent data or domain knowledge. AlphaGo Zero beat AlphaGo Lee (the version of AlphaGo that beat the world champion) 100 games to nil. What’s more, it achieved this feat in just three days of training. AlphaGo Zero is the product of machine learning methods that start from minimal knowledge and surpass all existing competitors.
To achieve such a dramatic advancement, DeepMind ingeniously married two methods of machine learning together: Deep Q-Learning and Monte Carlo tree search, a field of mathematics developed during the Manhattan Project. This process bypasses the need for evaluation functions, the innovation that made machines capable of defeating human champions at Go (before that, chess was solvable with simpler evaluation functions). In essence, using Monte Carlo simplifies predictions by assigning probabilities by running more efficient ‘look-aheads’ (possible outcomes), meaning it can estimate the best move more effectively by simulating close to 2000 look-aheads per turn.
Ultimately, AlphaGo Zero, and its successor AlphaZero, use the Deep Q-Learning ConvNet acts as their algorithmic ‘intuition’, while Monte Carlo tree search is the brute force operation engine for ‘look-aheads’. Both elements combine to form a vastly superior algorithm than what humans are capable of achieving. What’s more, AlphaZero has another over-powered trick. By playing itself 5 million times in a simulation, AlphaZero can develop its convolutional ‘wisdom’ from scratch. So the machine, which already has super-human learning abilities, also has the power of super-human iterations. The shortest games of Go are 20 minutes and the longest are many hours (professional matches have a 4 hour cap). By this measure, AlphaZero has played between 100 million and 1.8 billion minutes of Go, or somewhere between 230 and 3400 years. This takes ‘mastery’ to a new dimension.
This realm of severely super-human performance is awry to say the least. A machine capable of annihilating the greatest known champion without showing signs of weakness is incomparable to its opponent by nature. Without any such comparators, humankind cannot grasp the real capacity or beauty of their new champion. To further train an algorithm that reached this level for a full week seems frightening, let alone for months or years of training time. This is the same fear we should have about the singularity.
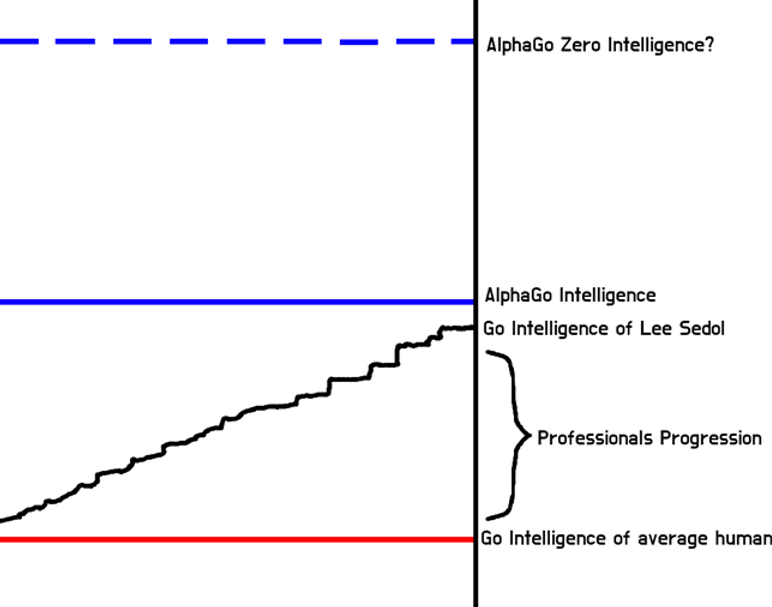
Figure 11. Super-human intelligence is near-impossible to measure, but this is a demonstration of the level DeepMind achieved with Go.
In 2017, Google’s Transformations made designing deep neural network architectures less resource-intensive. Additionally, the release of Tensorflow, PyTorch, VastAI, Keras and Flux.jl give wide public access to advanced machine learning tools. [10]
That same year, 48% of Chinese venture capital went to AI startups. China published 6x more patents than the US in deep learning. The Chinese government announced in July that it planned to reach the level of the US in AI by 2020 and become the world leader within 12 years. Voice assistants were rolled out as chatbots, with Google assistant phonecalls. Amazon Echo, Google Home, and Bixby were said to expect connection with all smart home products and LG made all of its appliances WiFi-enabled.
DeepMind in 2019 began using Temporal Value Transport (TVT) to help algorithms ‘understand the long term consequences of a decision that can be taken in the present. This was developed for use by AlphaStar.
2020s
Long before the turn of the decade, investment has been pouring into machine learning. Big tech has aggressively pursued the economic value hidden behind solving neural networks, and progress has accelerated. The chances of another AI winter are pretty comfortably out the question as neural nets have become integrated more deeply in the functions of our daily behaviour and generate ever more revenue for the companies funding their development.
In 2020, DeepMind announced MuZero, an algorithm capable of mastering Go, chess, shogi and Atari without needing to be told the rules thanks to its ability to ‘look-ahead’ in unknown environments. This was a major instalment to DeepMind’s sequence of unsupervised algorithms capable of learning on their own.
That same year, OpenAI showcased GPT-3, an auto-regressive natural-language-processing neural network, which, seeded with a few sentences, can generate impressively accurate text matching the style and content of the initial few lines. GPT-3’s capacity to generate synthetic propaganda lead to its labelling as the world’s ‘most dangerous’ algorithm by the Independent. This political danger threat is similar to that posed by deepfakes. [11]
In 2021, Facebook developed SEER (Self-SupERvised), a billion-paramter self-supervised computer vision model. It can learn from images without the need of labelling, tested on Instagram images. This is an early example of a flexible, accurate and adaptable neural net advanced enough for real-world usage.
Alphabet introduced Isomorphic Lab, a drug-discovery company using AI partially governed by DeepMind founder Dennis Hassabis. The collaboration of these companies suggests impressive breakthroughs are on the horizon. Google also announced they would be making Vertex AI publicly available; a managed machine learning platform for the deployment of AI models. Tensorflow 3D was also launched, a platform specifically effective at training and deploying 3D scene understanding models.
In 2022, OpenAI, a proponent of the safe rollout of AI, unveiled DALL-E 2; a programme to ‘fill in the blanks’ with a level of applied context that is undeniably similar to that of a human. The following image was generated by DALL-E 2 from the prompt: “A photo of proud racoon artists posing next to their painting.”

Figure 12. “A photo of proud racoon artists posing next to their painting”.
The applied context here is extraordinary; from the positioning of the scene; the posing of the two distinct racoons before an easel, brush in a paw suggesting fresh paint; to the questionable quality of the painting itself, every faucet of this image create an impressively convincing realism for the photograph-resolution image. Without a doubt, it is executed more convincingly than the average graphic artist.
The engine behind the aesthetic appeal of DALL-E 2’s flawless image generation is called “Aesthetic Quality Comparison,” and was achieved by training a separate algorithm to predict ‘human aesthetic judgements’ using a dataset known as AVA (Aesthetic Visual Analysis; a dataset of images with many dimensions of aesthetic scores and categorizations). DALL-E 2 produces 2048 images with a high mean-predicted aesthetic judgement score almost instantaneously and at low cost.
Elon Musk, one of OpenAI’s founders, said Tesla essentially had to solve ‘real-world AI’ to deliver self-driving cars, expected to roll out in the late year. Full Self-Driving (FSD) is a long-awaited benchmark for artificial intelligence, and its successful launch will enable great productivity gains for modern workforces.
Part III. The AI Pantheon
Machine learning seems to have developed at a startling rate, but during the deep winters of AI, the following springs did not seem inevitable. The hype-train has derailed AI research many times. But since the turn of the century, and specifically since 2012, hype has remained optimistic, with ever more rollouts of indispensable technologies and many ‘holy-shit moments,’ for the public and researchers alike.
The advancements in sub-symbolic architecture that have made these developments possible are simply long chains of problem solving. Many powerful algorithms in the modern age are now formulated with the marrying of a path-searching system and a neural network that learns through iteration and by experience, and the more powerful simulations become, the more intelligent machines are capable of becoming.
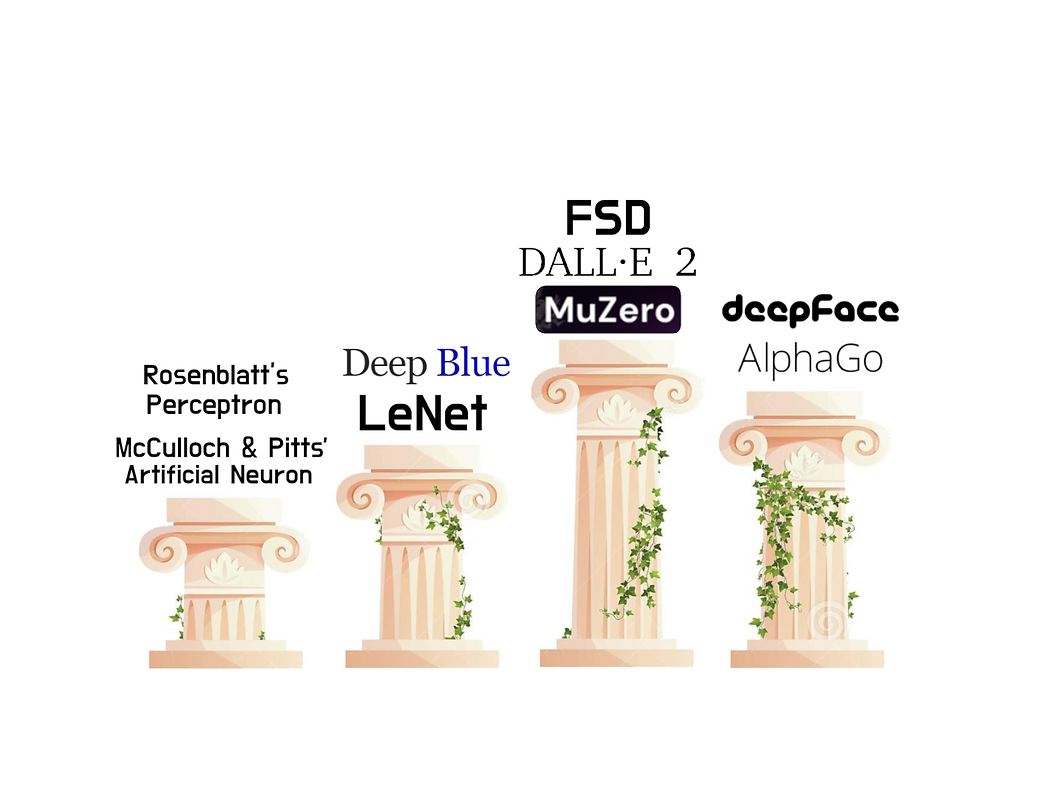
Figure 13. The Patheon of AI: Four Generations of Algorithm.
So, where to?
There are moral and ethical issues on the horizon for society, and many avenues for innovation for research. But the building blocks of intelligent algorithms are crystallised, and the algorithms of the future are predictable by connecting blocks. A creative writing algorithm generating highly compelling stories could train with an engine for generating visual cinematography to output compelling stories for the silver screen, with a perfect balance of curious directorial decisions and nostalgic predictability to captivate ratings. By pairing this algorithm with an audio engine for realistic voice-overs and an engine that takes subtle queues from the script to form an emotive soundtrack, the product could be a fully-fledged, photo-realistic movie, unbounded by classic effects and stunt budgets.
If that sounds unlikely, study the progression of OpenAI’s DALL-E project. All it took was a high quality dataset to go from the first version’s uncompelling visuals to the threateningly efficient version two. DALL-E 3 could conceivably generate GIFs and soon after: videos. By this iterative process, a machine becomes magnitudes more impressive. A streaming service may one-day be offered for spontaneously generated movies, or movies generated for your personality and preferences, rendered in real-time in a cloud computer facility while you watch on your smartphone. I hope to explore these potentials with this series on Intelligence.
For a more technically complex breakdown of machine learning, check out this paper by Favio Vazquez.
And for a deep-learning centric breakdown, this is excellent by Juergen Schmidhuber.
Notes
[1] - A great breakdown of McCulloch and Pitts’ function is available here.
[2] - The Mark 1 perceptron was used for image recognition. It was connected to a camera with 20×20 cadmium sulfide photocells to make a 400-pixel image. The main visible feature is the patch panel that set different combinations of input features, which is what you can see in the picture. To the right, arrays of potentiometers would then implement the adaptive weights. Read the journal article here: https://link.springer.com/book/9780387310732.
Rosenblatt’s paper: Rosenblatt, F. : Principles of neurodynamics. Washington, D.C. : Spartan Books 1962.
[3] - A.G. Ivakhnenko’s paper: (1971). Polynomial theory of complex systems. IEEE Transactions on Systems, Man and Cybernetics, (4):364–378.
[4] - For versions of this story, look here and here.
[5] - https://www.rctn.org/bruno/public/papers/Fukushima1980.pdf
Fukushima published this in a cybernetics journal, incidentally. “Cognitron: a self-organizing multilayered neural network” Cybernetics 20, 121-136 (1975). See here.
[6] - Fast Company’s timeline on AI history here.
[7] - Read about the bug in Deep Blue’s software on the Wired archive.
[8] - In 2016, Kasparov noted that you can buy a chess engine for a typical laptop that could beat Deep Blue quite easily. He also admitted that he had a lot more respect now for the team behind Deep Blue, his “beef” was with IBM.
[9] - Find the low human estimate under section 6.4 of this paper. It is widely cited, despite its obscurity.
[10] - Check the impact on legendary Arxiv… https://arxiv.org/abs/1707.04873.
[11] - The Most Dangerous Algorithm in the World! The Independent.