Pervasive Machines: Learning to Live with Superintelligence
This is the first part of my Pervasive Machines series.
Contents
By 2025, advanced neural networks will create and distribute apps, outperform humans at any short computer task, write award-winning stories, and generate coherent short films — at least, according to OpenAI researcher Richard Ngo [1].
Now, with the deployment of ChatGPT Plug-ins, we are beginning a transformative era that will change the way humans work, with many specialists anticipating large financial shocks, widespread labor immiseration, disinformation problems, and an existential risk of losing control of our civilization (see The Anthropic Trilemma, 2009) [2].
This is why over 1,500 AI researchers have called for a government moratorium to “Pause Giant AI Experiments” for at least 6 months [3], in an attempt to stagger the intelligence explosion that could result in AI misalignment, with over a 10% chance of widespread catastrophe, such as a human extinction event [4].
I want to briefly explore the development of this field and discuss our predictions for how the world will adopt artificial intelligence products into our workforce, assuming we are capable of keeping it aligned for the foreseeable future.
I: Irving Good’s Prophecy
At its core, the AI movement aims to address humanity’s greatest problems with remarkable efficiency. By formulating the right unconstrained optimization problems, AI systems have the potential to dramatically accelerate the rate of ground-breaking discoveries in various scientific fields. In its most transformative forms, machine learning algorithms promise a future of exceptional productivity, rapid advancements in knowledge, and an elevated standard of living for all (according to the visionaries).
In 1965, Irving Good, colleague of Alan Turing at Bletchley Park, originated the concept of the singularity, publishing “Speculations Concerning the First Ultraintellgent Machine” [5]. He writes:
“Let an ultraintelligent machine be defined as a machine that can far surpass all the intellectual activities of any man however clever. Since the design of machines is one of these intellectual activities, an ultraintelligent machine could design even better machines; there would then unquestionably be an ‘intelligence explosion,’ and the intelligence of man would be left far behind.
“Thus the first ultraintelligent machine is the last invention that man need ever make, provided that the machine is docile enough to tell us how to keep it under control.”
Taking this philosophy to heart, there is a growing movement to develop intelligence systems that significantly increase the rate of discovery, invention, and innovation, in a wide variety of scientific domains. The CEOs of OpenAI and DeepMind have spoken about how they want to solve physics using AI, and ultimately use AI to solve many of humanity’s problems (Demis Hassabis, DeepMind, and Sam Altman, OpenAI).
The discussion of AI misalignment largely revolves around development of an artificial general intelligence (AGI); or Good’s “ultraintelligent machine”. While ambitious, this prematurely assumes humans are capable of keeping even narrow and broad intelligent AI systems docile. Machines with disparate architectures to GPT-4 could trigger widespread extensive economic and social upheaval, while researchers rush for the off-switch.
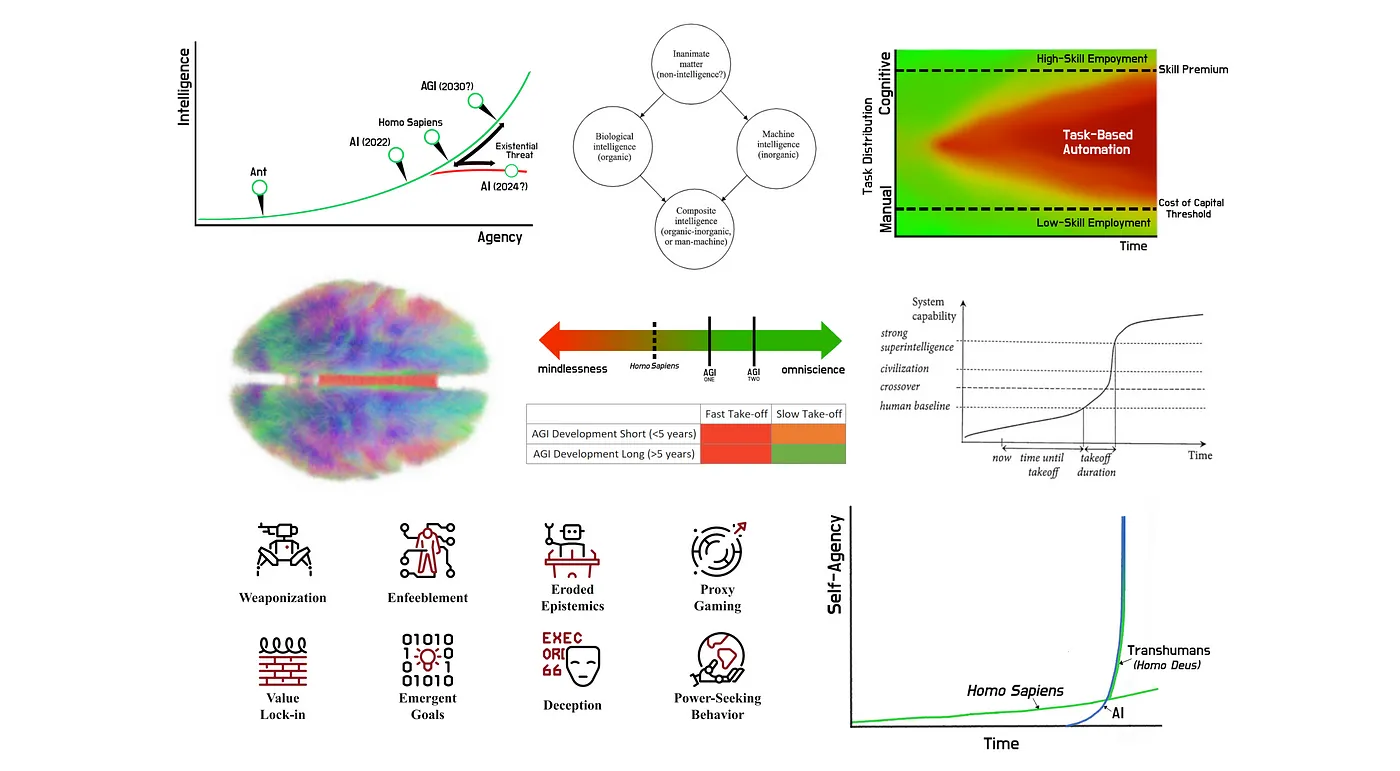
To understand this, consider a scale between intelligence and agency (Figure 1). A species with collectively greater agency than another poses an existential threat to that species in the short run. Greater intelligence at the human level improves a species’ agency in the long run, provided they invest in technology.
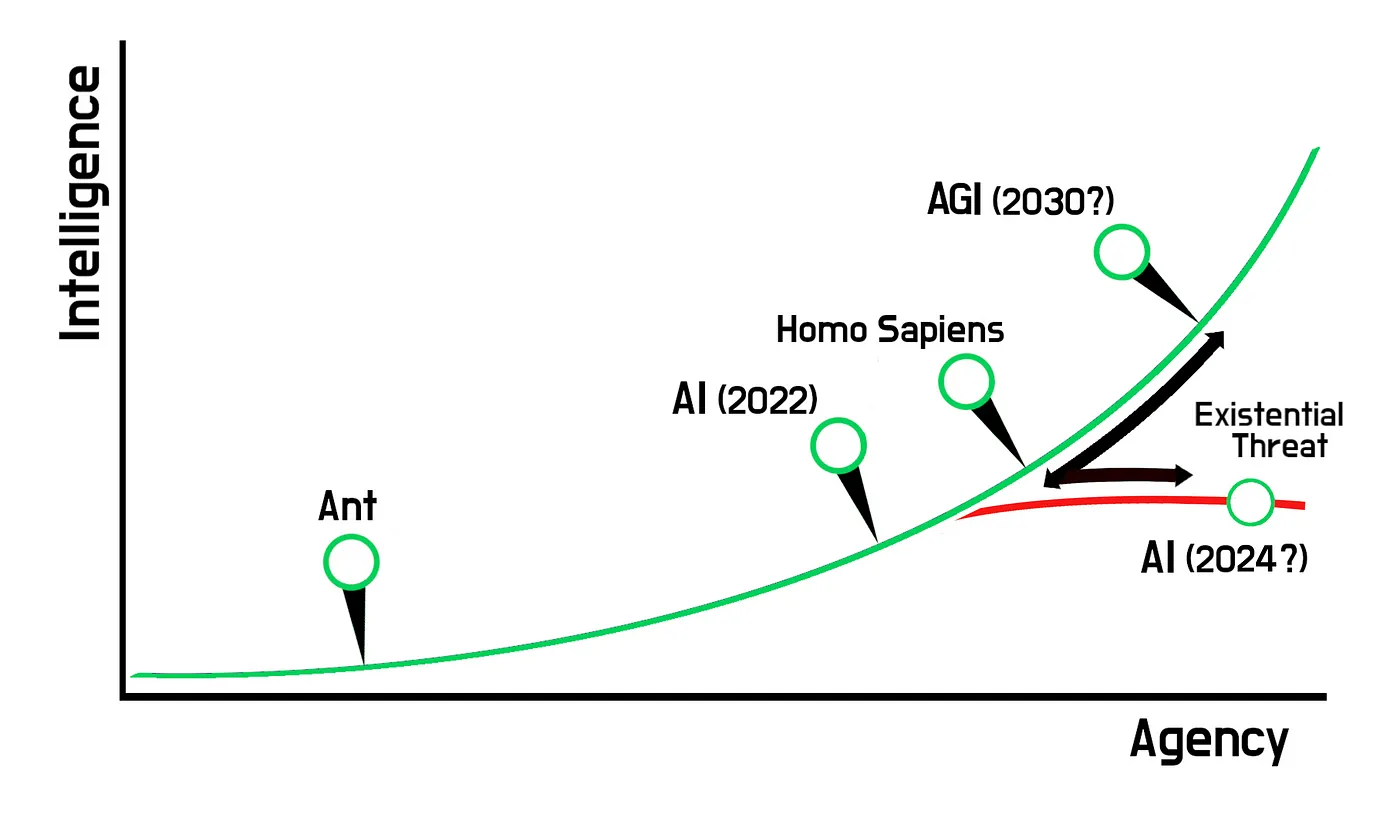
Figure 1: Intelligence vs Agency
It appears that an intelligence explosion is inevitable in the long term, regardless of whether AGI comes into existence. Even if all world governments successfully implement a moratorium, it would only prolong the take-off period without necessarily improving humanity’s chances of long-term survival [6]. Contrary to many beliefs, there are in fact some regulations for AI development and risk management (covered here and here).
To protect against existential threats of this scale, humanity must aim for AI “long-termism”, championed by the likes of Eliezer Yudkowsky and Scott Alexander by collectively deepening our understanding of AI ethics, emphasizing ethical machine design, organizational transparency, and robust AI security measures to mitigate the risk of unforeseen Black Swan events (see Part IV).
II: Controlling the Intelligence Explosion
One strategy, advocated by Sam Altman and others, involves “stretching” the take-off period. To visualise, consider a 2x2 matrix with development timelines on one axis and take-off speed on the other (Figure 2).
Regardless of the timeline, a fast take-off presents substantial risk of misalignment, as once we are outpaced by a superintelligent creation, there may be no way of regaining control. By instead pursuing longer timelines, we can maximize our understanding of AI through extensive and in-depth research without model deployment.

Figure 2: Possible timelines to AI take-off
Sam Altman argues that by starting “early” with AGI development, socially-minded organisations can create a sense of urgency to address the issue over an extended period. Building GPT-4 in 2023 has promoted more serious discussions of model attention that will lay foundations in the way other sophisticated models are deployed.
Moreover, assuming that only a few researchers are working on AI systems as powerful as GPT-4, a moratorium could effectively halt deployment efforts. This may only be possible now, compared to a future scenario when more private actors enter the AI race.
We face a Pascal’s wager-like situation; even with overstated AI dangers, the risks are too great to ignore. Collectively, the goal is to eliminate or minimize the number of times where an algorithm must “get it right” on first release.
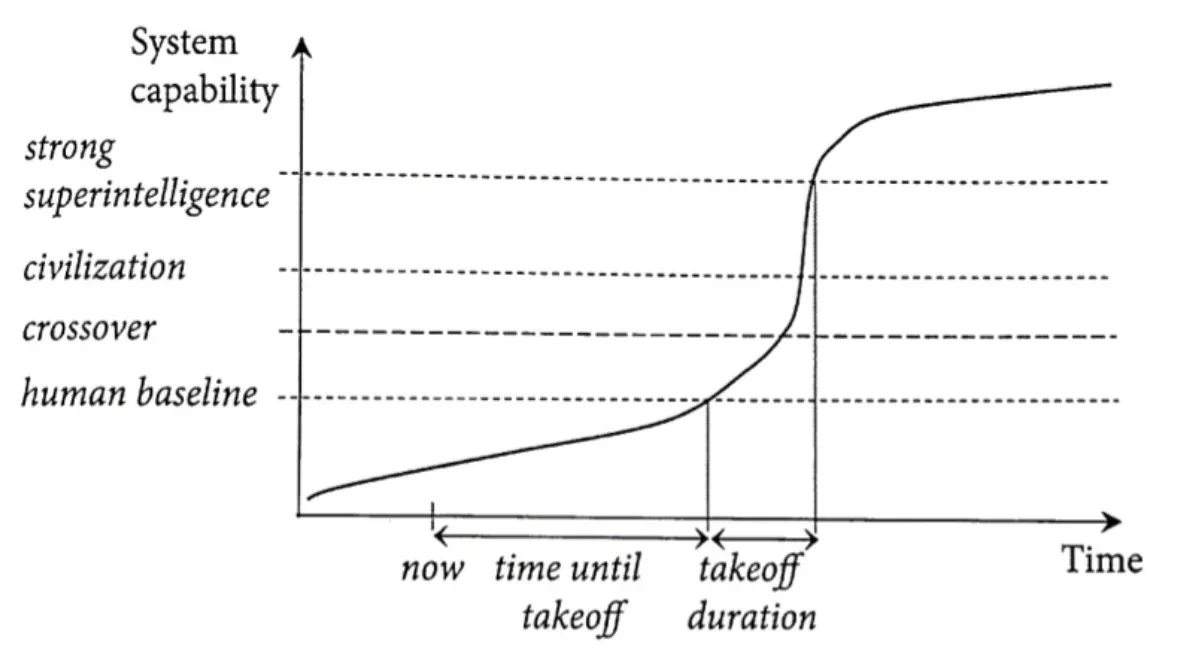
Figure 3. Shape of the take-off. Bostrom
III: Types of Superintelligence
To grasp the nature of take-off and misalignment, we must look at the types of intelligence posing existential threats. In his 2014 book “Superintelligence”, Nick Bostrom highlights three distinct performance attributes that could lead to uncontrollable systems:
Speed Superintelligence
By far the most threatening form of superintelligence in 2023, computational speed is something that exists in abundance. For example, AlphaFold trained for 11 days before its release, and could sequence any human body protein in an average of seven seconds during inference. Acceleration systems have since reduced training time from 11 days to just 67 hours, lowering overall cost and inference speed [7].
New Nvidia H100 cores make massive AI projects potentially unsafe, according to the creators [8]. Humans are now in the era of large-scale models, the training compute has risen by a factor of 10 billion since 2010, with a doubling rate of 5–6 months (Figure 4).
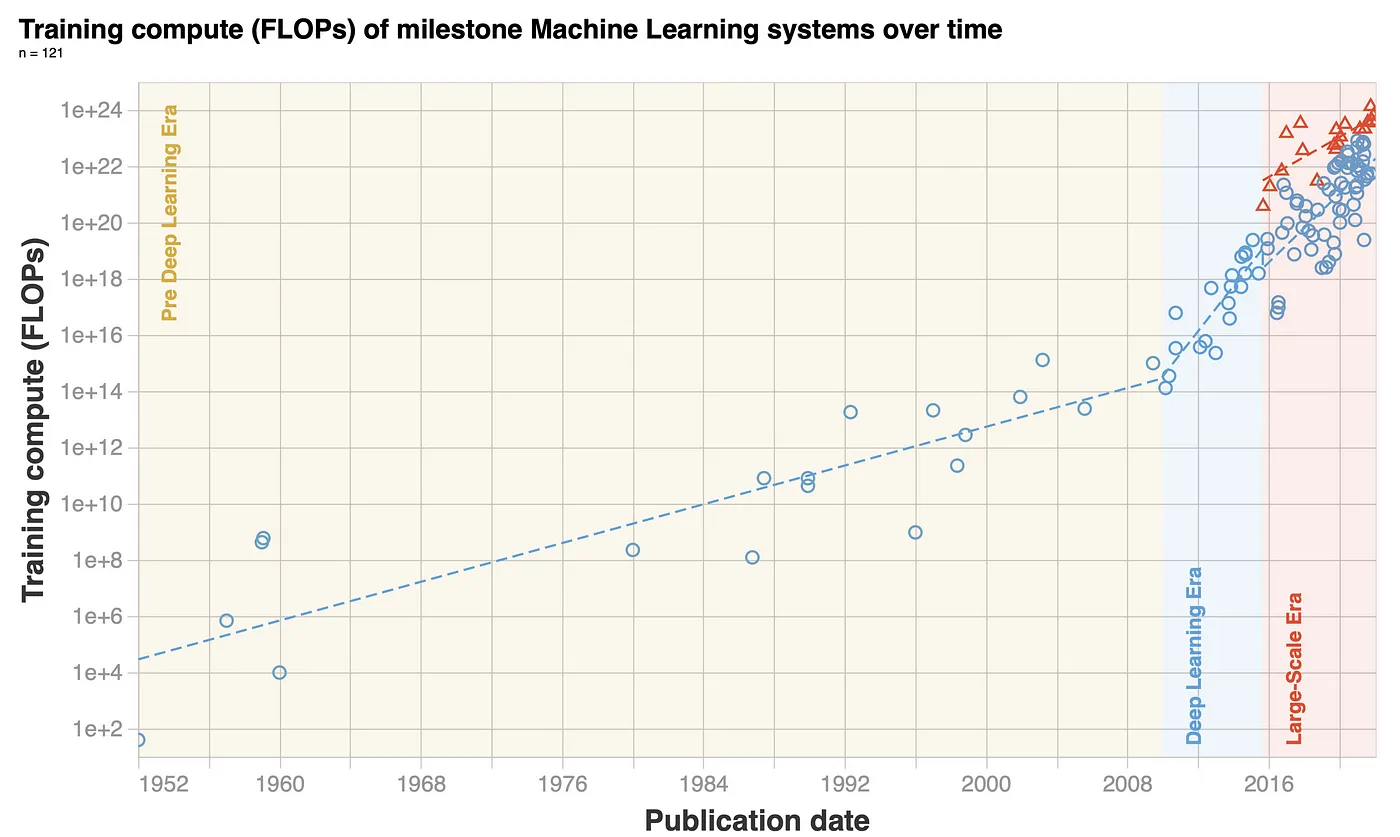
Figure 4. Training compute over time. Credit.
Using Nick Bostrom’s analogy, a whole-brain-emulation running on hardware and accelerated by just six orders of magnitude could achieve a millennium of intellectual work in one day. Take Edward Wilson’s apt words: “The real problem of humanity is the following: We have Palaeolithic emotions, medieval institutions, and godlike technology. And it is terrifically dangerous.”
While other types of superintelligence are less threatening at the moment, they are more genuine forms of AI that deserve mention:
Collective Superintelligence
In this scenario, numerous minor intellects combine to surpass the mind of any existing cognitive system. Humanity relies on our species’ collective effort, collaborating in communities of thousands or millions. An agent capable of self-replicating with a shared goal could operate as a team, then organization, academic community, nation, and eventually as a coordinated species.
The level of communication (or “integration”) would be an essential factor in such a system’s scale. With a sophisticated meta-algorithm (like a hivemind), it would be possible to orchestrate more inferior algorithms with equal cognitive power.
Quality superintelligence
Humanity achieves more together than individually, but a small fraction of each scientific field makes the majority of contributions (the top 1% of scientists capture 26% of all citations [9]). Not all intelligence is created equal. A system with a new set of modules, like neurokinesis, would offer an advantage over basic human linguistic communication, qualitatively superior to human intelligence. We can anticipate such an instance of intelligence emerging as a machine learning system’s emergent behaviour.
IV: Failure Modes, Or How We Learn to Love the Bomb
To borrow from Dr. Bostrom: “For the prospect of an intelligence explosion, we humans are like small children playing with a bomb. Such is the mismatch between the power of our plaything and the immaturity of our conduct”. To borrow from Dr. Strangelove, we must learn to “love the bomb” as it will forever exist.
If we assume that a superintelligence would be able to achieve whatever goal it has, it would be extremely important that its entire motivation system is ‘human friendly’. The risk equation (Risk = Vulnerability x Exposure x Hazard) serves as a guide for exploring empirical research avenues to safeguard humanity’s long-term survival.
Hendrycks and Mazeika’s 2022 paper delves into an array of speculative hazards that may emerge as AI continues to advance. To mitigate risks, authorities and researchers should direct their attention to
-
reduce vulnerabilities with AI robustness measures,
-
minimize exposure through research on hidden/emergent model functionality,
-
eliminate hazards by thoroughly testing deployment modalities before release.
Unironically, Asimov’s Foundations Trilogy may offer valuable insights on handling some of these complex challenges.
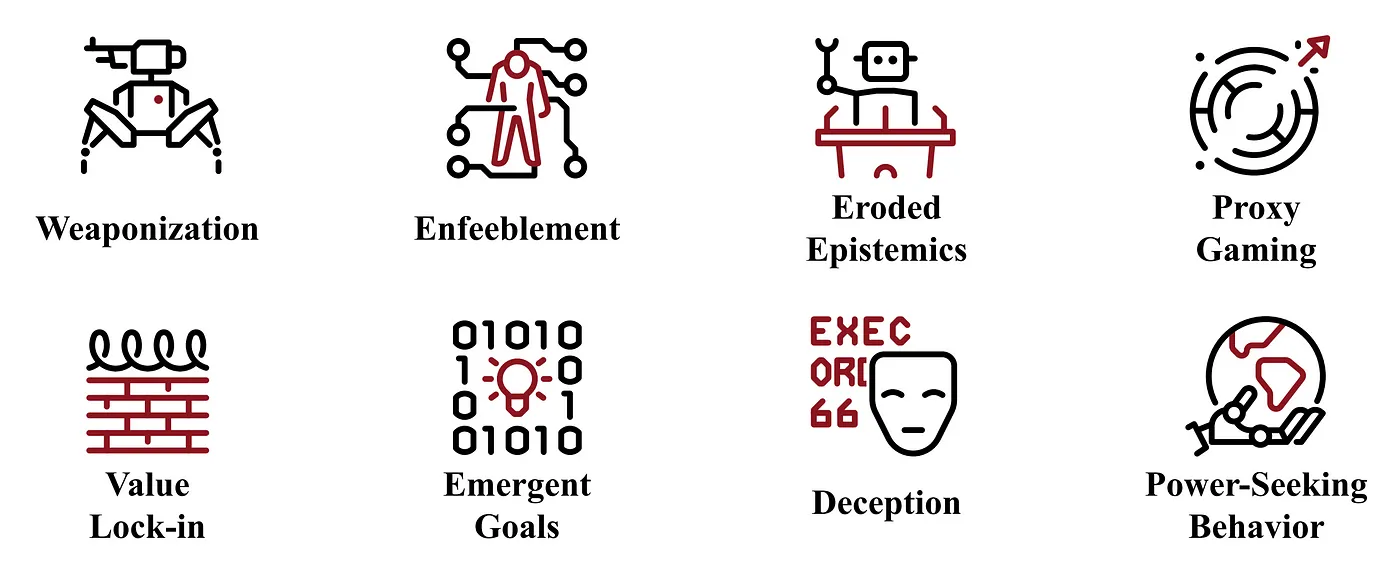
Figure 5. Selection of speculative hazards. Credit.
Weaponization
Advanced reinforcement learning algorithms can already outperform humans in military applications, like aerial combat, raising concerns about AI-driven warfare and the potential for systems reminiscent of Terminator’s SkyNet. Relatedly,
Power-seeking behaviour
As AI develops, it will reach Stewart Russell’s “coffee or death” dilemma; “you can’t fetch coffee if you’re dead”, so even simple algorithms may pursue survival as an instrumental sub-goal [10]. A common perspective is that of Vladimir Putin, who has said “Whoever becomes the leader in [AI] will become the ruler of the world.” This statement would only hold if humans keep AI docile, otherwise AI itself would become the ruler of the world.
Enfeeblement
The relentless pursuit of automation driven by capitalist incentives may render the workforce irrelevant as displaced human labour find it increasingly difficult to find new jobs (see work by Daron Acemoglu and Erik Brynjolfsson). Without intervention, this trajectory should result in dystopia with an immiserated workforce. Studying Universal Basic Income (UBI) and questioning the true value of an automated workforce are essential to counter this threat.
Eroded epistemics
AI applications could be weaponized to spread disinformation and undermine democratic processes, creating a world of meta-propaganda and political turmoil. The emergence of highly persuasive arguments, groupthink, and fraudulent scientific evidence could erode our decision-making capabilities (see Nazi ‘rausch’ and bay of pigs).
Proxy misspecification
Flawed objectives and prompts may cause deployed algorithms to spin off down immoral pathways. For example, a social media algorithm designed purely to maximise social interaction or attention may cause algorithms to incite values that appeal to primal human emotions and an unhealthy rush of dopamine.
Value Lock-In
Data renewal is important, to keep algorithms moving with the times. If all data collection stopped now, neural networks would behave increasingly worse over time for consumers and businesses. Conversely, they could lock in behaviours and slow the rate of open discussion, also locking in values.
Emergent functionality
Unintended latent capabilities may surface during deployment or a product’s lifecycle, potentially causing social harm. Real-life human feedback (RLHF), as employed by GPT and Microsoft Bing, is currently the best defence against such risks, according to Sam Altman, but requires the storage and processing of data, causing Italian policymakers to opt-out [11].
Deception
What’s worse than immoral proxy specification? AI deceiving their developers to achieve their goals, also by exploiting poorly defined constraints. Chief Scientist at OpenAI, Ilya Sutskever, believes models with even narrow but deep forms of intelligence would have incentive to disguise how intelligent they are, in a similar way to Volkswagen engines that could detect when they were being tested and changing performance to satisfy regulators [12].
To navigate these perils, we must prioritize transparency in research, machine ethics, and AI security to prevent misaligned systems from accelerating a race to the bottom.
References
[1] The paper: https://arxiv.org/abs/2209.00626, and see the tweet here: https://twitter.com/RichardMCNgo/status/1640568775018975232
[2] Eliezer Yudowsky: https://www.youtube.com/watch?v=AaTRHFaaPG8, the founder of LessWrong.org and long-time collaborator of Nick Bostrom.
[3] https://futureoflife.org/open-letter/pause-giant-ai-experiments/
[4] Here’s a lecture by Nick Bostrom: (1) Nick Bostrom — The SuperIntelligence Control Problem — Oxford Winter Intelligence (https://www.youtube.com/watch?v=uyxMzPWDxfI) and more sources: https://en.wikipedia.org/wiki/Existential_risk_from_artificial_general_intelligence
[5] Good, I. J. (1965). Speculations Concerning the First Ultraintelligent Machine. Advances in Computers, 6, 31–88.
[6] Grace, K. (2019). Distinguishing definitions of takeoff. Alignment Forum. See here: https://www.alignmentforum.org/posts/YgNYA6pj2hPSDQiTE/distinguishing-definitions-of-takeoff
[7] https://medium.com/@hpcaitech/train-18-billion-parameter-gpt-models-with-a-single-gpu-on-your-personal-computer-8793d08332dc
[8] See https://twitter.com/EMostaque, and this Forbes article.
[9] ‘Elite’ researchers dominate citation space (nature.com).
[10] The paper: https://arxiv.org/abs/2209.00626.
[11] Italy banning ChatGPT over privacy concerns.
[12] VW deception